

Em machine learning, dataset não é apenas "entrada". Ele é a primeira versão da verdade operacional do sistema.
É por isso que gosto da forma como este projeto documenta os dados. O dataset não fica escondido atrás de um comando genérico de treino. O repositório explica de onde ele vem, como os splits funcionam e o que os labels significam na prática.
A Fonte dos Dados
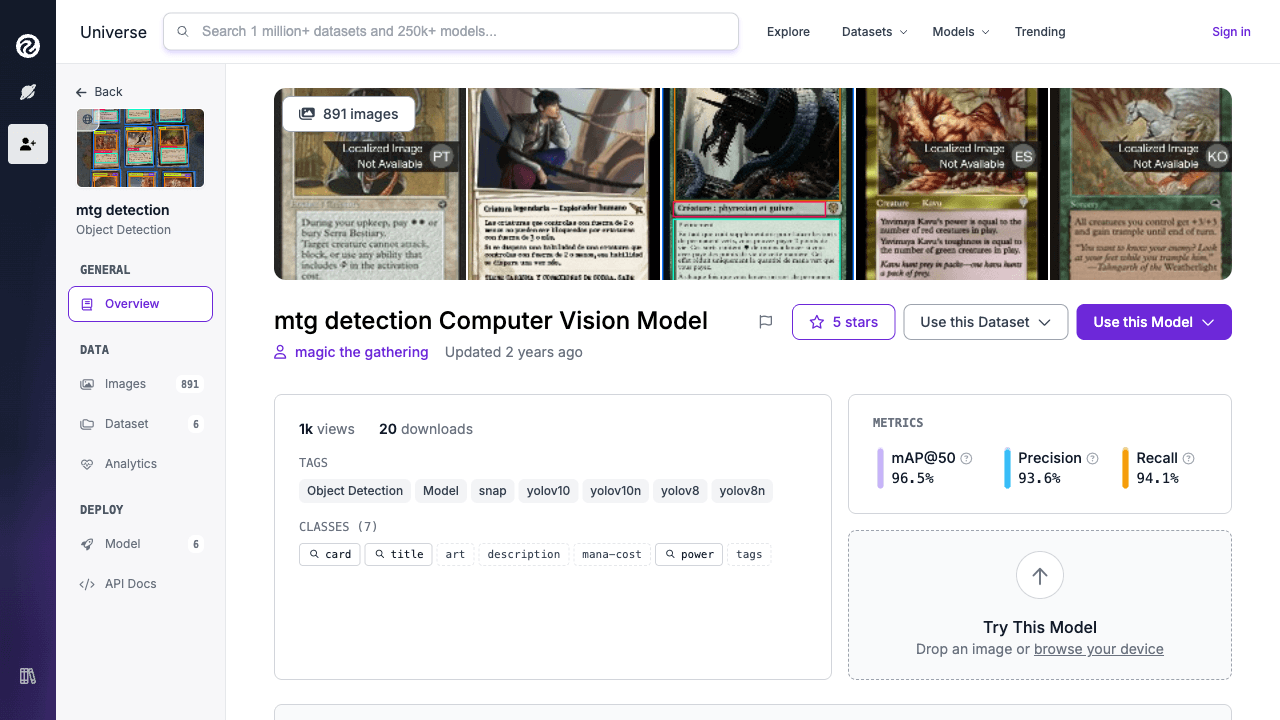
O projeto usa um dataset do Roboflow Universe voltado para regiões de cartas de Magic: The Gathering. O detalhe importante não é só a quantidade de imagens, mas o fato de as anotações serem regionais, e não apenas no nível da carta inteira.
Isso significa que o modelo está aprendendo a estrutura visual do objeto, não apenas a presença de uma carta em cena.
A Estratégia de Splits
O repositório segue a divisão clássica em três subconjuntos:
train: onde o modelo aprendevalid: onde o progresso de treino é acompanhadotest: onde a avaliação final precisa permanecer honesta

Essa separação importa porque um detector que performa bem em imagens que praticamente memorizou não tem utilidade como produto.
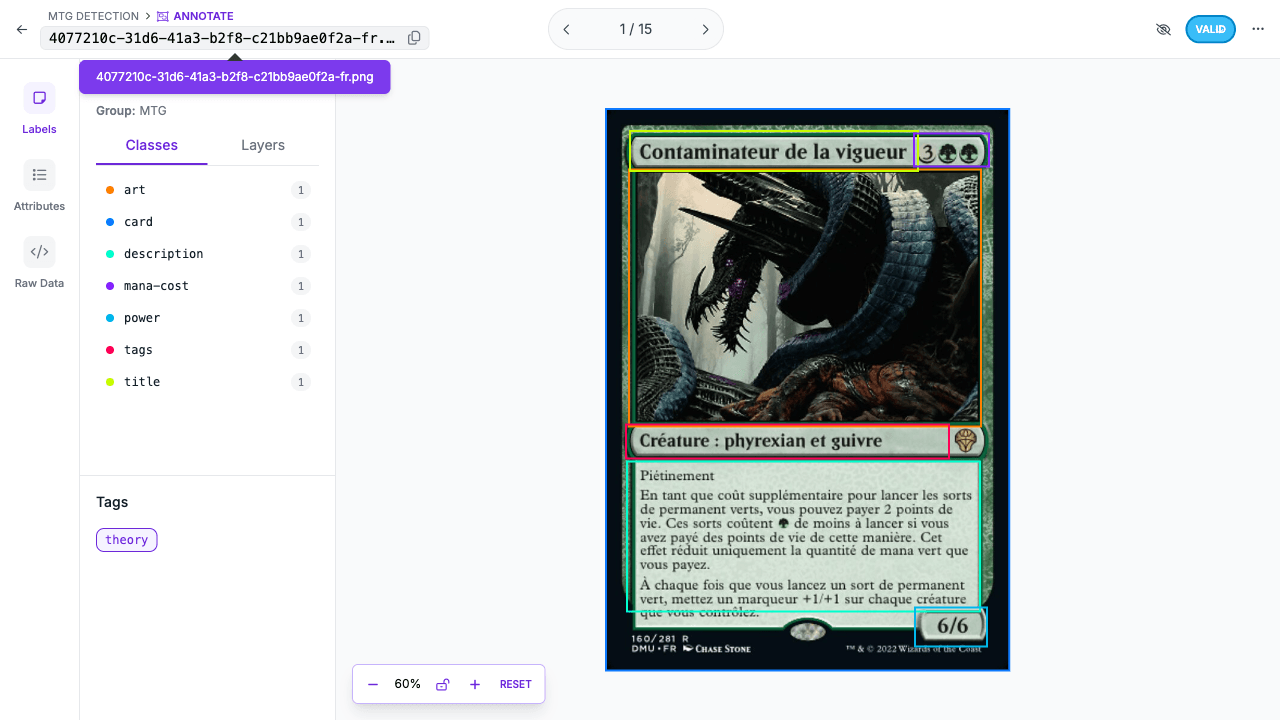
As Sete Classes
O conjunto de classes é simples, mas revela muito sobre o desenho do sistema:
artcarddescriptionmana-costpowertagstitle
Isso não é um detector genérico de cartas. É um detector desenhado para servir um pipeline posterior. title existe porque o OCR precisa de um crop limpo. art existe porque a desambiguação visual de impressões depende de uma região específica. As classes refletem as necessidades do produto, e não uma organização arbitrária.

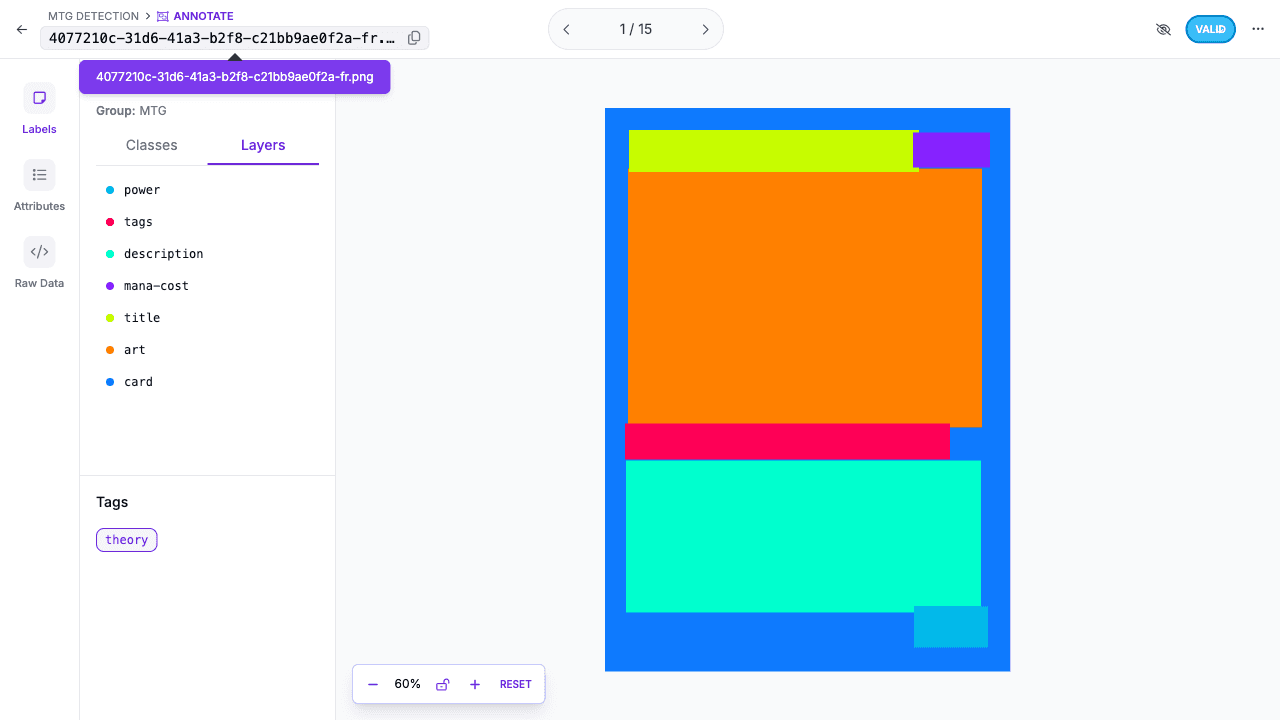
O Que Um Label YOLO Guarda
O formato de label é enxuto:
Todas as coordenadas são normalizadas para o intervalo [0, 1].
Essa simplicidade é uma vantagem prática. O mesmo formato também é impiedoso com labels ruins. Se a caixa estiver inconsistente, o modelo vai aprender exatamente essa inconsistência.

Ruído de Anotação É Gargalo de Verdade
Um dos sinais mais úteis deste projeto está no desnível entre métricas relaxadas e métricas estritas. Quando mAP50 é forte, mas mAP50-95 cai de forma relevante, isso costuma indicar que o detector encontra a região correta de forma geral, mas não consegue manter caixas muito precisas sob critérios mais rigorosos.
Esse efeito pesa ainda mais em regiões pequenas como mana-cost e power. Em caixas grandes, um pequeno erro de coordenada mal aparece. Em caixas pequenas, o mesmo erro muda muito o IoU.


É por isso que modelos maiores nem sempre resolvem o problema certo. Se o limite estiver nos labels, aumentar a capacidade do modelo pode apenas fazê-lo memorizar melhor um alvo imperfeito.
Checagens de Qualidade Valem Mais do Que Parece
Os scripts de exploração deste repositório não são acessórios. Eles ajudam a responder perguntas fundamentais:
- há labels faltando?
- algumas classes aparecem pouco demais?
- as caixas pequenas estão soltas ou apertadas demais?
- treino e validação representam o mesmo mundo?
Sem esse tipo de checagem, tuning vira superstição cara.
O Loop de Correção É Parte da Arquitetura
Outro acerto do projeto é explicitar o ciclo de melhoria dos dados:
- exportar predições
- revisar exemplos
- corrigir labels
- reincorporar os dados corrigidos
- retreinar
Isso mostra maturidade. O modelo não é treinado uma vez e abandonado. Dataset e detector evoluem juntos.
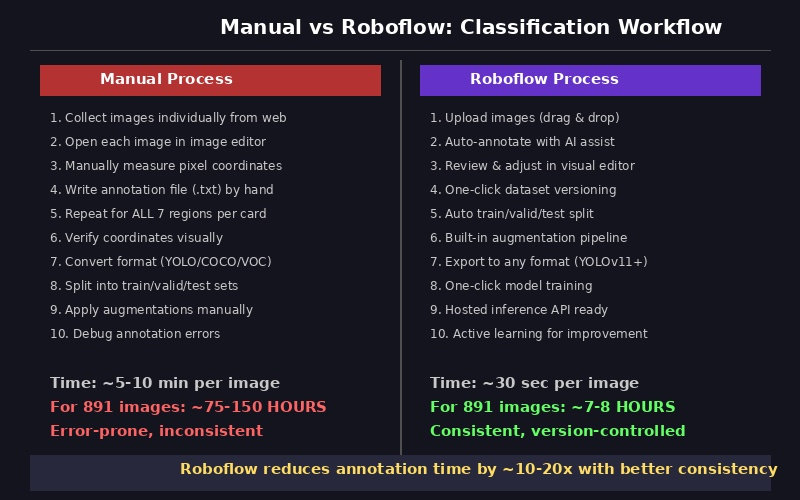
Esse é o custo de base. Ele explica por que ferramentas assistidas são valiosas, mas também por que confiar cedo demais em automação costuma sair caro depois.
A leitura correta não é "automação substitui julgamento". É "automação comprime a primeira passada, para que a revisão humana se concentre nos casos difíceis".
Conclusão
Um detector aprende a definição de realidade que o dataset impõe. Se os labels forem consistentes e alinhados ao problema, o modelo tem chance de ficar forte. Se os labels forem ruidosos, a evolução vai estagnar mais cedo do que parece.
Este repositório acerta ao tratar dataset e labels como artefatos de engenharia de primeira classe.
Na próxima parte, saímos dos dados e entramos no treinamento: transfer learning, augmentations, otimização e os experimentos que empurraram o detector até o melhor resultado.
Leituras adicionais
- Arquitetura e formatos de dados:
docs/architecture.md - Conceitos e divisão dos dados:
docs/concepts.md - Guia de métricas:
docs/metrics-guide.md - Documentação do Roboflow: https://docs.roboflow.com/