

Métricas sem interpretação são apenas numerologia cara.
O valor deste projeto é justamente mostrar que os números fazem sentido quando lidos à luz da geometria das classes e do pipeline inteiro.
Precision e Recall
As duas perguntas centrais são simples:
- quando o detector prevê uma região, com que frequência ele está certo?
- quando a região existe de fato, com que frequência ele a encontra?
Essas respostas moldam diretamente a confiança do produto.

Em outras palavras: precision fala sobre o custo dos falsos positivos. Recall fala sobre o custo dos falsos negativos. Um produto bom precisa entender os dois, não apenas celebrar o maior número disponível.
mAP50 vs mAP50-95
mAP50 responde a pergunta: o modelo encontrou aproximadamente a região certa?
mAP50-95 endurece o critério: ele exige caixas muito mais bem localizadas e consistentes ao longo de thresholds mais rígidos.
O desnível entre essas métricas é especialmente revelador em projetos como este. Se mAP50 é forte, mas mAP50-95 cai bem, o detector provavelmente está enxergando o lugar certo, mas ainda falha na precisão fina da caixa.

Classes Pequenas Sofrem Mais
Nem todo erro de pixel custa a mesma coisa.
Em art, um pequeno deslocamento quase não altera o IoU de forma dramática. Em mana-cost ou power, o mesmo erro muda muito o resultado. É por isso que classes pequenas quase sempre sofrem mais sob métricas estritas.
Esse ponto é importante porque evita uma leitura simplista de "o modelo é ruim em objetos pequenos". Às vezes o que existe é uma combinação de:
- labels ligeiramente inconsistentes
- regiões visualmente difíceis
- penalização maior do IoU em caixas pequenas
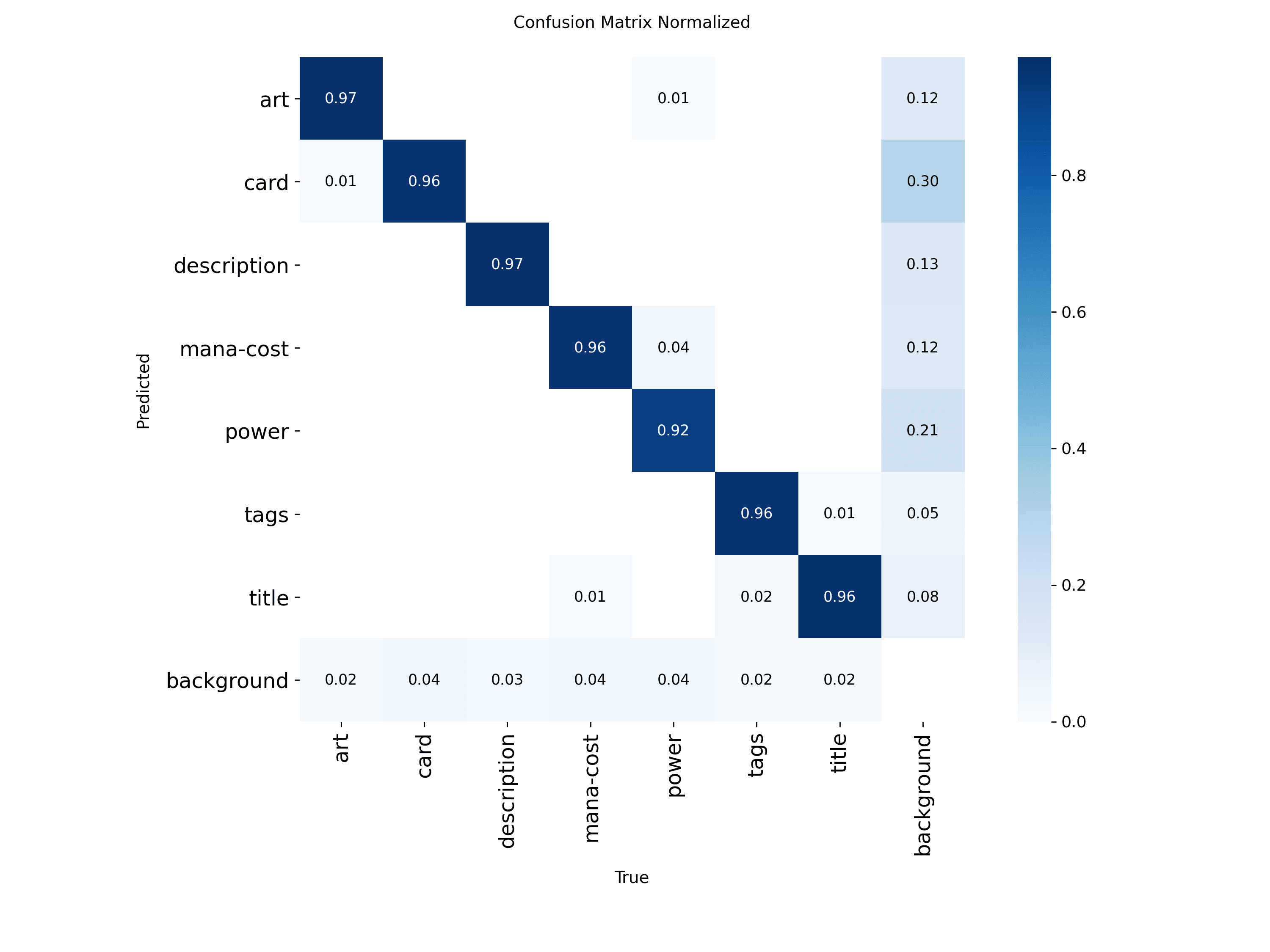
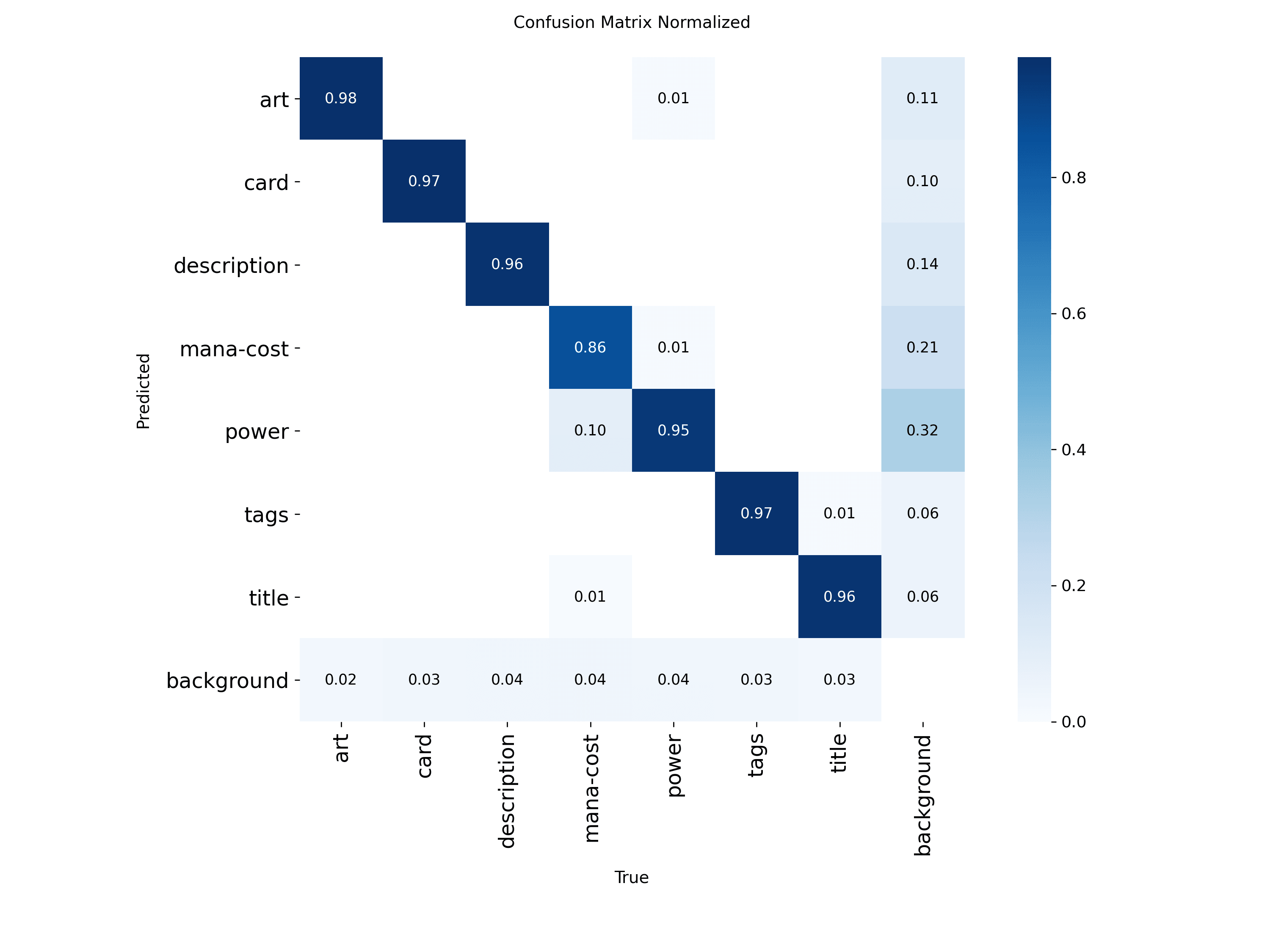
Métrica Só Faz Sentido Com Produto
O que interessa mesmo é o efeito no resto da cadeia:
titlealimenta OCRartalimenta DINOv2- uma caixa ruim pode degradar tudo o que vem depois
Por isso, ler métricas direito é perguntar: em quais regiões o sistema precisa ser excelente para continuar útil?
Curvas Que Viram Decisão
As curvas são mais úteis quando ajudam a tomar decisões concretas.
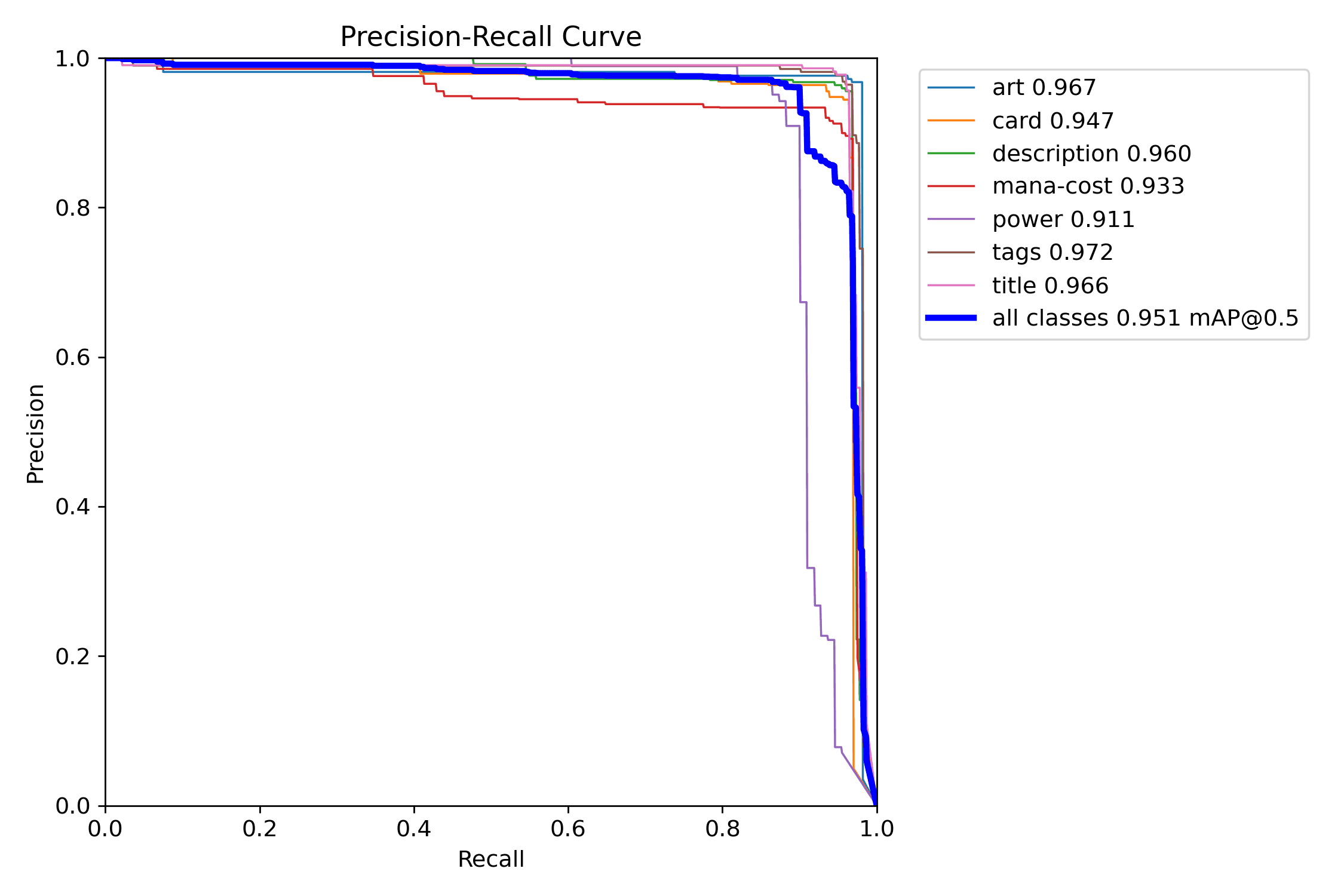
A curva PR ajuda a responder a pergunta maior primeiro: o detector continua útil quando tentamos recuperar mais regiões reais?
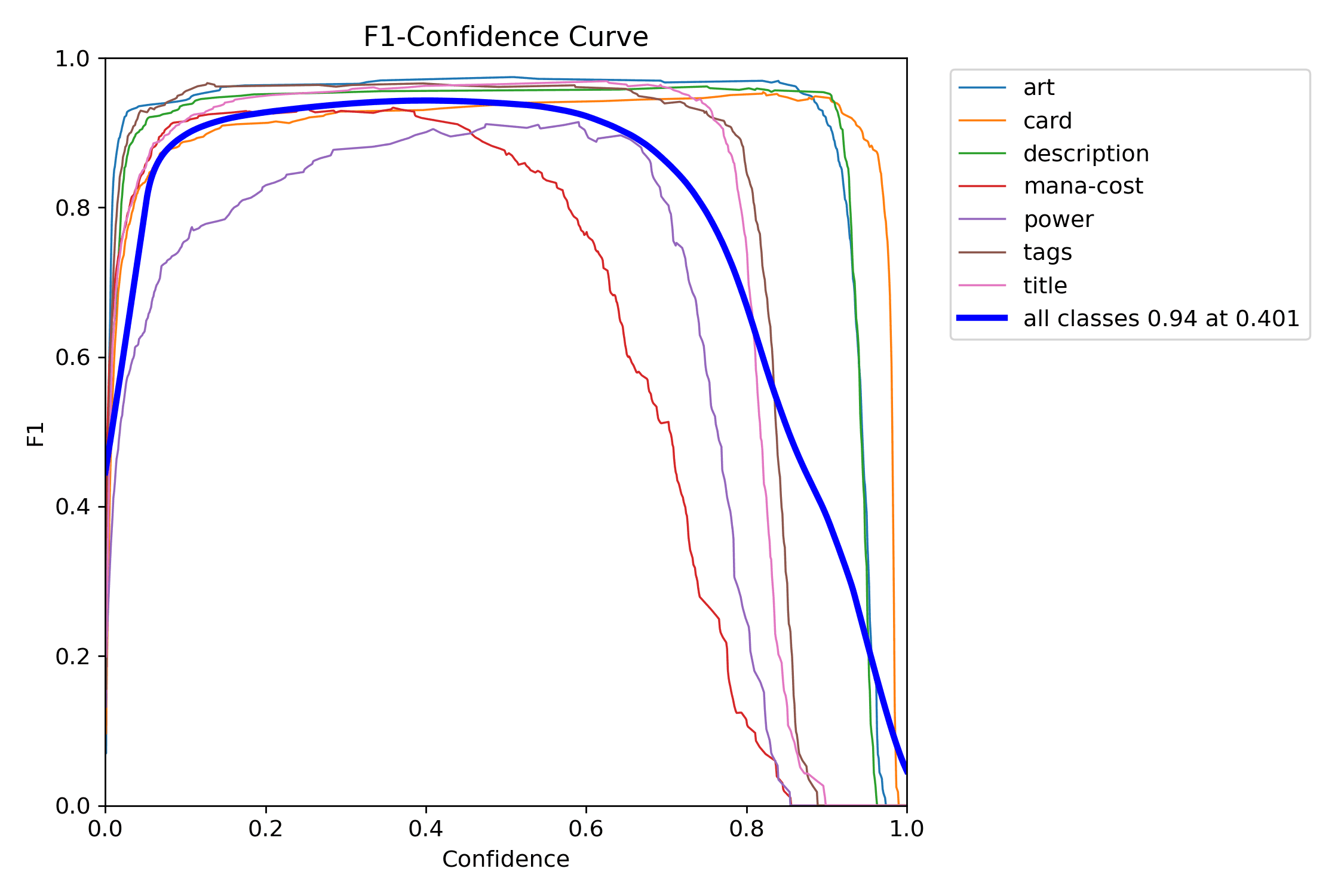
A curva F1 é ótima para escolher um ponto de operação sem chute. Ela mostra onde o equilíbrio entre precision e recall fica mais saudável para o caso real.
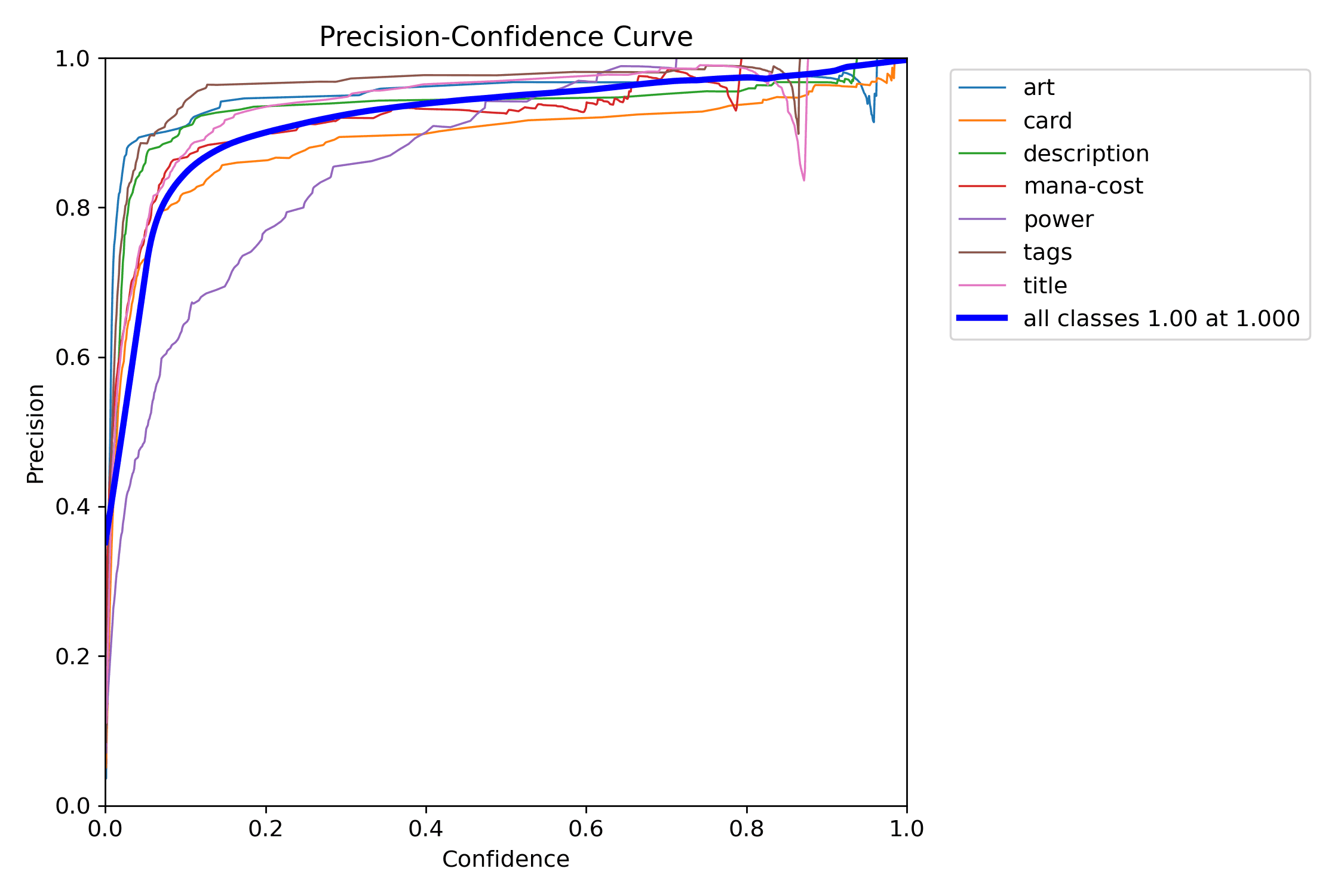
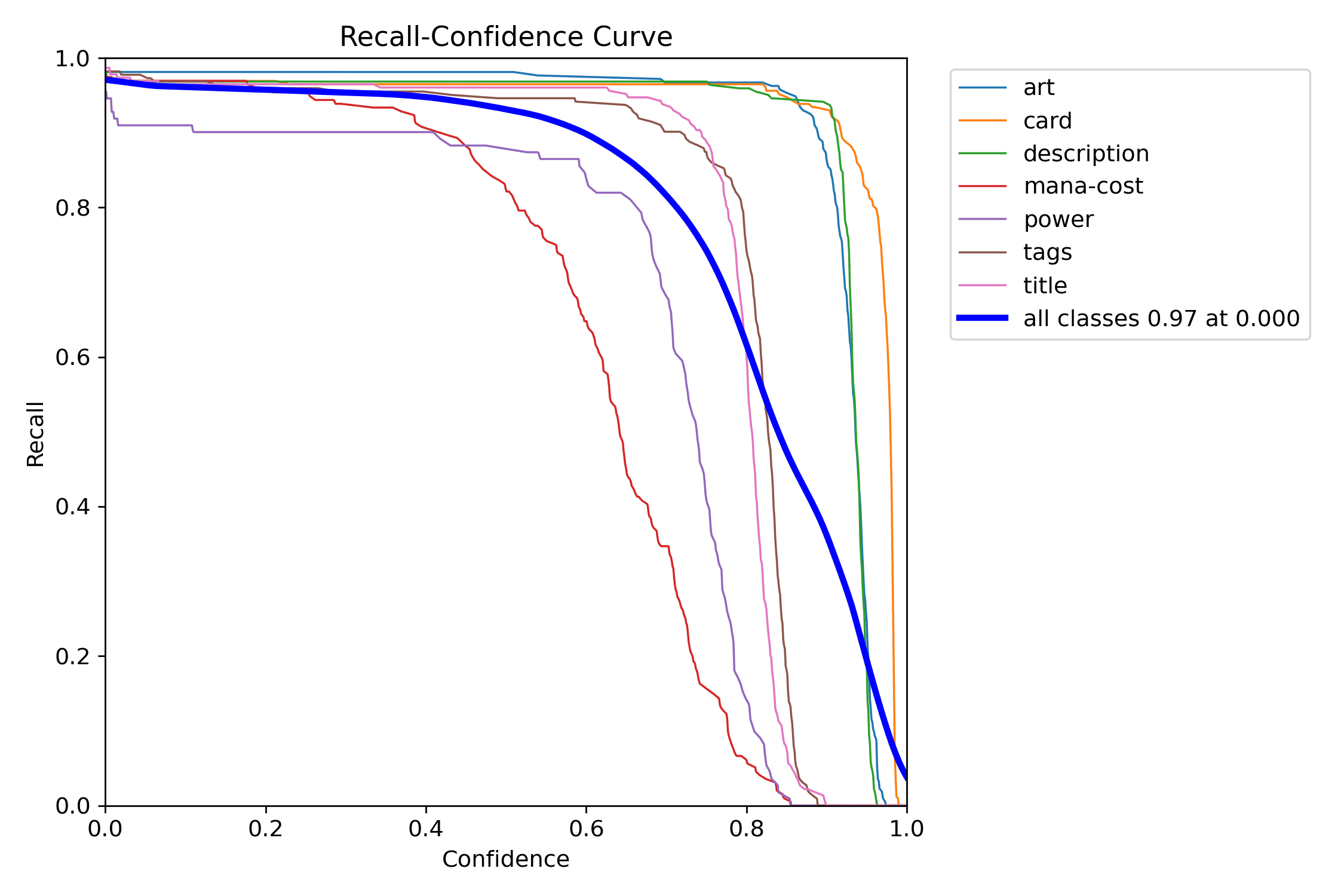
As curvas de precision e recall tornam a mesma decisão legível por lados opostos: uma mostra como falsos positivos caem; a outra mostra o preço pago em detecções perdidas.
Uma Boa Leitura de Métricas Gera Próximos Passos
Quando leio os resultados deste projeto, as decisões que surgem são claras:
- manter a baseline atual porque ela já é forte nas regiões que mais importam
- melhorar labels se o objetivo for elevar a qualidade de localização estrita
- evitar a suposição automática de que modelos maiores são o próximo passo certo
- pensar no pipeline inteiro, e não apenas no número final do benchmark
É isso que métricas boas deveriam produzir: direção de engenharia.
Conclusão
As métricas deste detector são valiosas não porque são altas, mas porque são interpretáveis. Elas permitem inferir onde o modelo é robusto, onde a localização ainda é frágil e onde provavelmente está o teto de melhoria.
É isso que transforma benchmark em engenharia.
Na próxima parte, seguimos a saída do detector até o pipeline de identificação, onde detecção vira OCR, lookup e matching visual.
Leituras adicionais
- Guia de métricas:
docs/metrics-guide.md - Solução completa:
docs/solution.md