

Esta é a parte em que o projeto deixa de parecer apenas um detector e passa a parecer um produto de verdade.
Quando o usuário vê nome, preço e impressão correta na interface, várias etapas independentes já trabalharam juntas:
- o detector separou as regiões úteis
- o OCR leu o título
- o Scryfall resolveu a identidade da carta
- o DINOv2 comparou a arte para distinguir a impressão
Esse encadeamento é o núcleo do sistema.
A Forma do Pipeline

O acerto arquitetural está em dar a cada etapa um trabalho estreito e defensável.
A Detecção Cria Estrutura
O detector não resolve a identidade da carta sozinho. O papel dele é transformar uma imagem bruta em regiões semanticamente úteis.
Isso importa porque OCR depende muito da qualidade do crop. Tentar ler a carta inteira de uma vez introduziria ruído demais: texto de regras, símbolos, bordas, fundo. O crop de title dá ao OCR um problema bem mais limpo.

OCR Transforma Pixel em Texto Utilizável
Quando o RapidOCR trabalha sobre o crop do título, ele recebe uma entrada muito mais controlada. É por isso que a combinação detecção + OCR é tão forte: um modelo resolve a localização espacial, o outro resolve a extração semântica do texto.
OCR sem detecção enxerga ruído demais. Detecção sem OCR ainda não sabe o nome da carta. Juntos, eles produzem uma etapa útil de verdade.
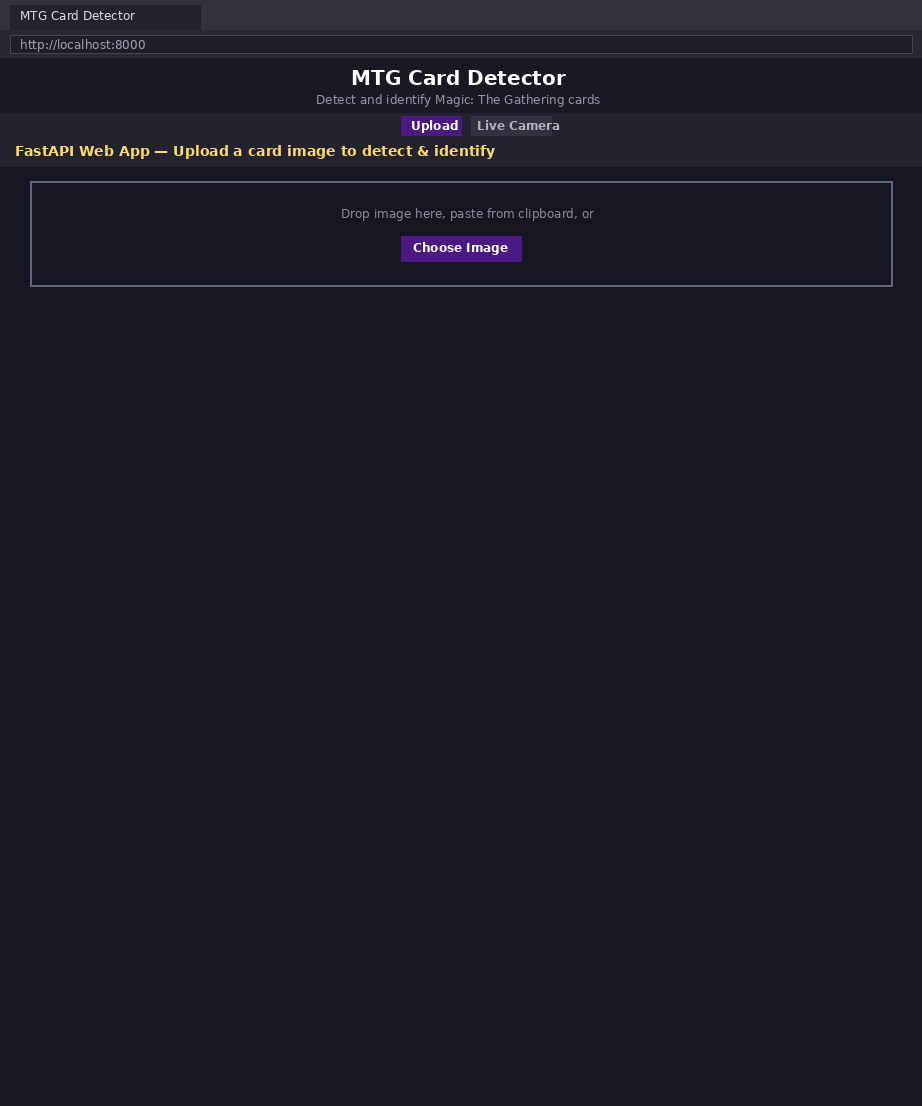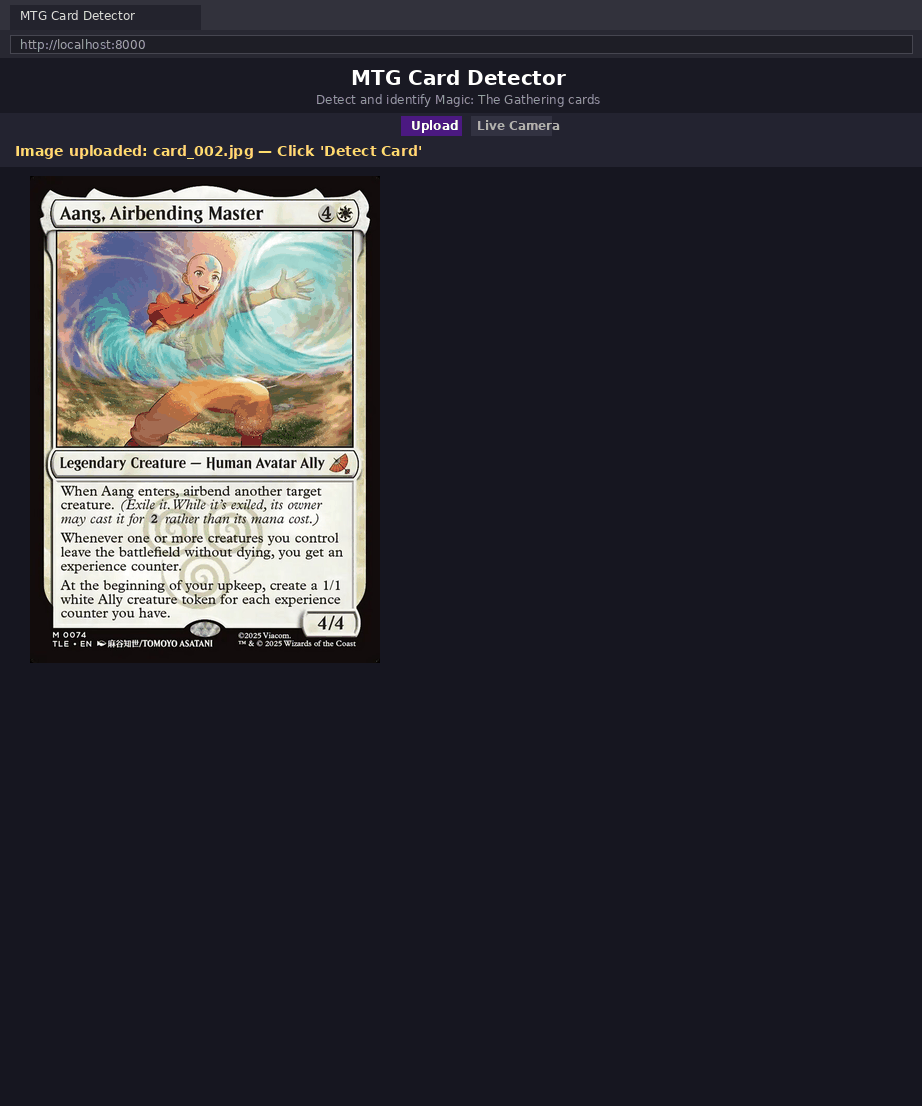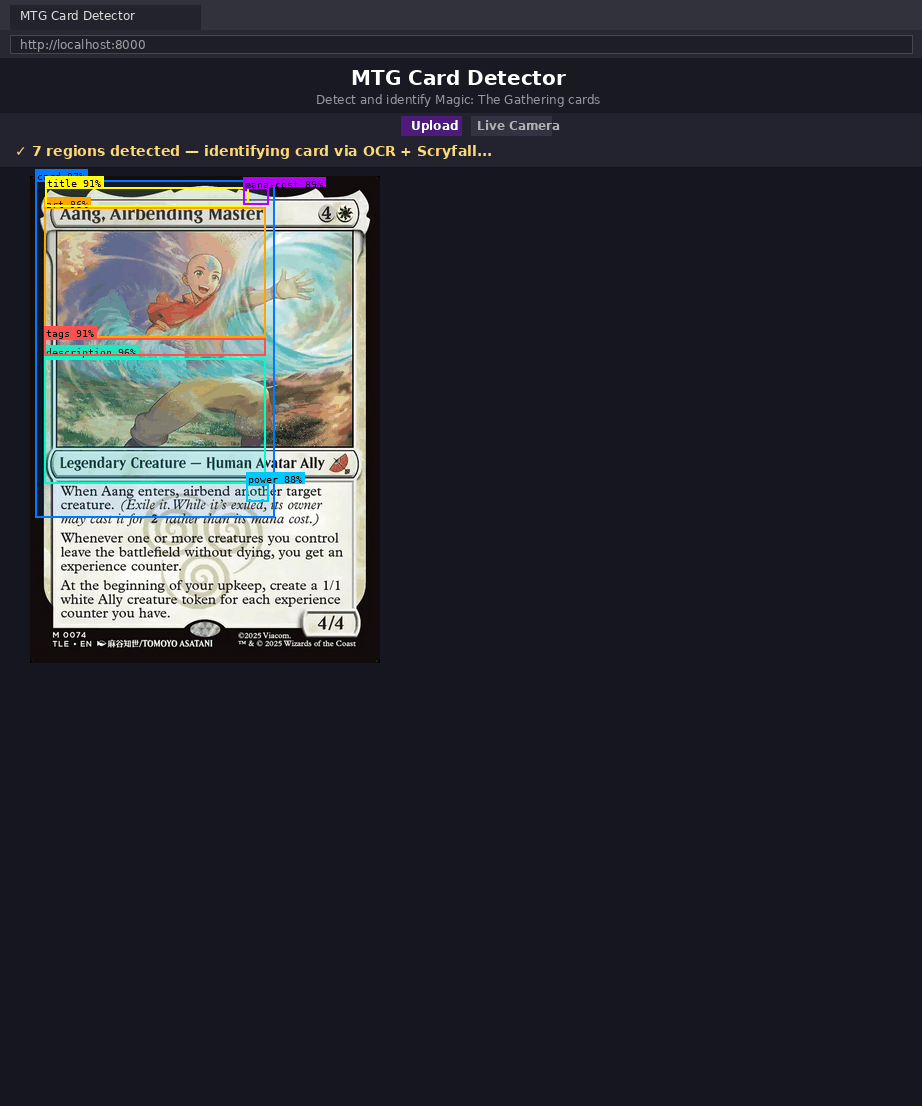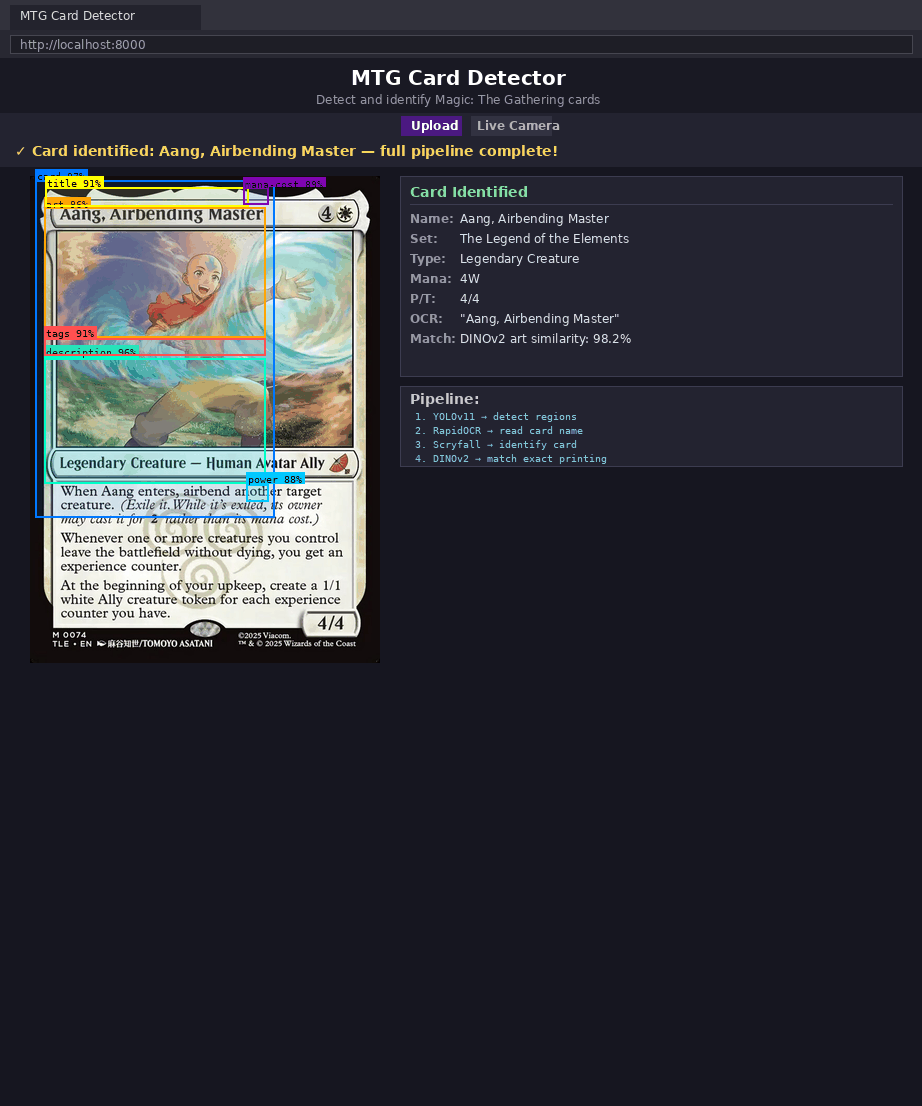
Scryfall Resolve a Carta
Quando o OCR gera um título candidato, o sistema consulta o Scryfall para fazer a resolução da identidade.
Essa é uma ótima decisão de arquitetura porque terceiriza uma base de conhecimento enorme para um serviço especializado:
- nomes canônicos
- oracle text
- preços
- printings
- imagens
O sistema local não precisa modelar tudo isso do zero. Ele só precisa transformar saída visual em uma consulta robusta.
DINOv2 Resolve a Impressão
Aqui o projeto fica especialmente interessante.
Texto costuma bastar para descobrir a carta. Nem sempre basta para descobrir a impressão. Cartas diferentes podem compartilhar nome e texto, mas variar em arte, edição e número.
É por isso que a classe art é tão importante. O crop da arte vira embedding e é comparado com embeddings das impressões candidatas.
Conceitualmente:
- recortar a arte da carta da imagem de entrada
- gerar um embedding desse crop
- gerar embeddings das artes candidatas
- comparar por similaridade
- escolher a impressão mais próxima
Isso é um bom exemplo de composição entre modelos especializados em vez de exigir que um único modelo faça tudo.

Propagação de Erros É o Risco Real
Pipelines são poderosos porque dividem um problema difícil em etapas. Também são perigosos, porque cada etapa pode degradar a próxima.
Esse é o risco central do sistema. Um ganho pequeno no começo da cadeia pode produzir uma melhora desproporcional no fim. Às vezes um crop melhor vale mais do que um modelo de matching mais sofisticado.
Por Que a Separação em Serviços Funciona
O diretório web/services/ reflete uma decomposição saudável:
detection.pyocr.pyscryfall.pyimage_match.py
Isso facilita depuração e evolução. Quando a resposta final sai errada, a equipe consegue perguntar:
- o detector encontrou mal o título?
- o OCR leu errado?
- o Scryfall retornou candidatos ruins?
- o DINOv2 escolheu a arte errada?
Essa clareza de fronteiras é exatamente o que um sistema em produção precisa ter.
A Melhor Lição de Arquitetura
O projeto acerta porque não confunde "IA" com "um modelo só". Ele combina as ferramentas certas para trabalhos diferentes:
- detector para estrutura espacial
- OCR para texto
- API de domínio para metadados canônicos
- modelo de similaridade para a arte
Esse jeito de compor o sistema é mais valioso do que qualquer escolha isolada de biblioteca.
Conclusão
Para o usuário, a experiência final parece simples. Para a arquitetura, ela só parece simples porque as responsabilidades foram bem separadas.
Detecção é a porta de entrada. Identificação é a orquestração que vem depois. Essa é a diferença entre uma demo de modelo e um produto utilizável.

Na última parte, vamos olhar para a aplicação web, os limites operacionais e o que realmente significa colocar esse sistema no ar.
Leituras adicionais
- Solução completa:
docs/solution.md - Serviço de detecção:
web/services/detection.py - Serviço de OCR:
web/services/ocr.py