

This is the chapter where the project stops looking like a detector and starts looking like a product.
By the time the user sees a card name, a price, and the exact printing, several independent systems have already cooperated:
- the detector found the relevant regions
- OCR read the title crop
- Scryfall resolved a card identity
- DINOv2 compared art crops to distinguish printings
That is a serious pipeline.
The Pipeline Shape
The solution document summarizes the core flow cleanly:
This architecture is effective because every stage has a narrow, defensible job.

Stage 1: Detection Creates Structure
The detector's job is not "solve card identity." Its job is to transform an unstructured image into semantically useful regions.
That matters because OCR quality depends heavily on crop quality. A generic OCR pass over the entire card would invite clutter from rules text, symbols, borders, and background noise. A targeted title crop gives the OCR engine a much cleaner problem.

Stage 2: OCR Turns Pixels into Searchable Meaning
The project uses RapidOCR to read the title region. That is an excellent pairing:
- detection handles spatial localization
- OCR handles text extraction
The combination is stronger than either one alone. OCR without detection sees too much noise. Detection without OCR still does not know the card's semantic identity.
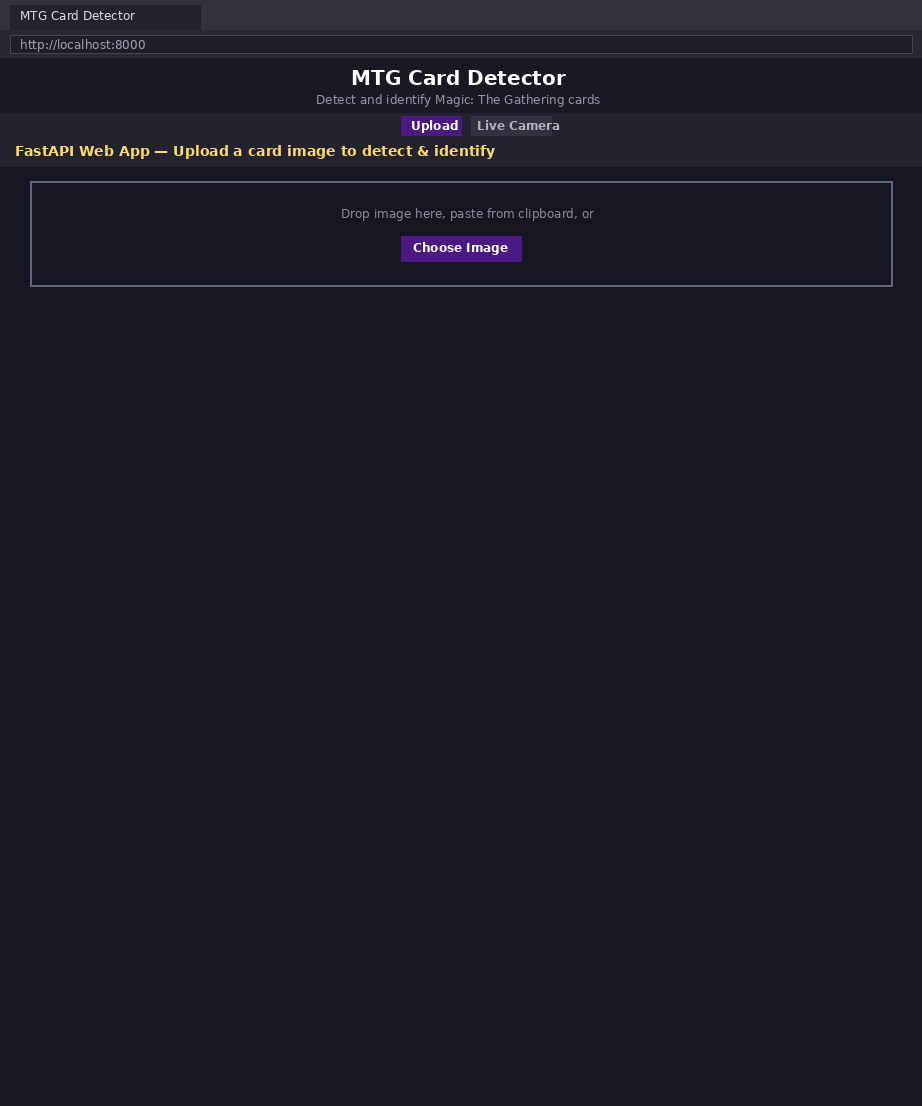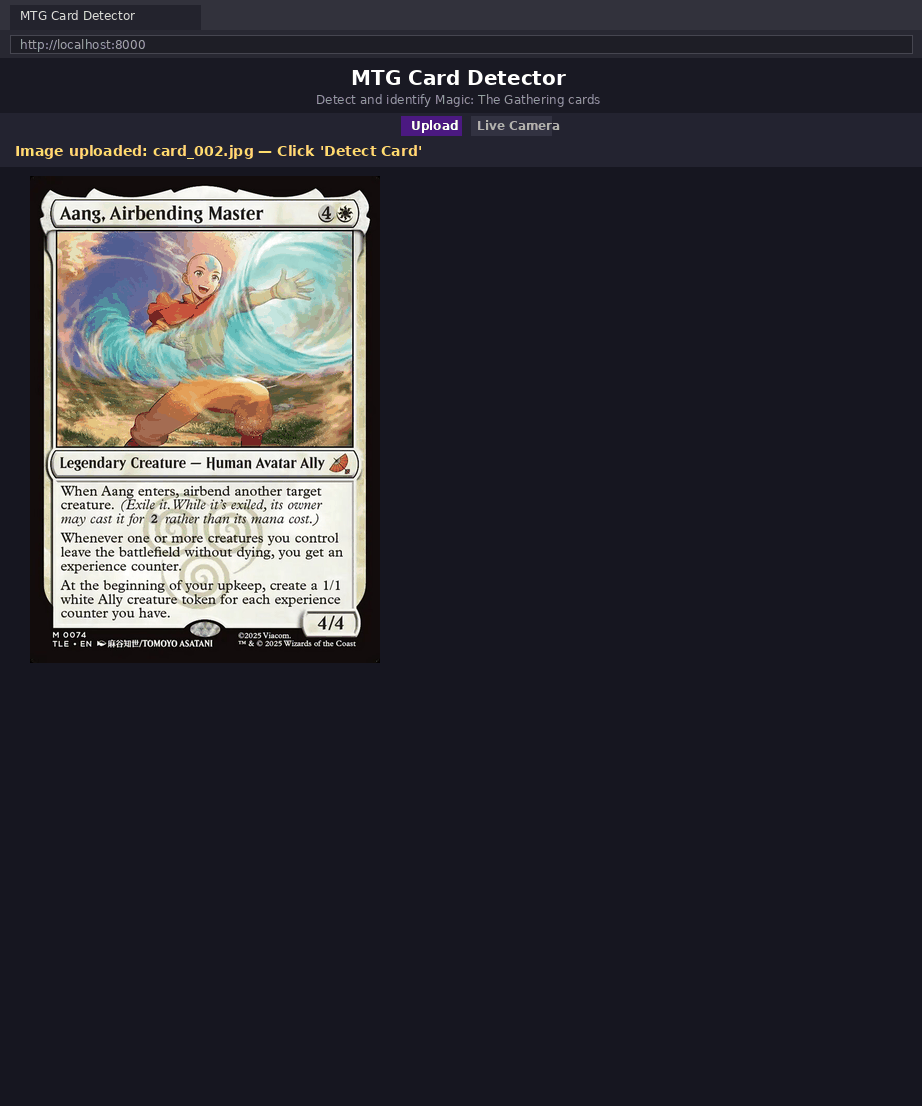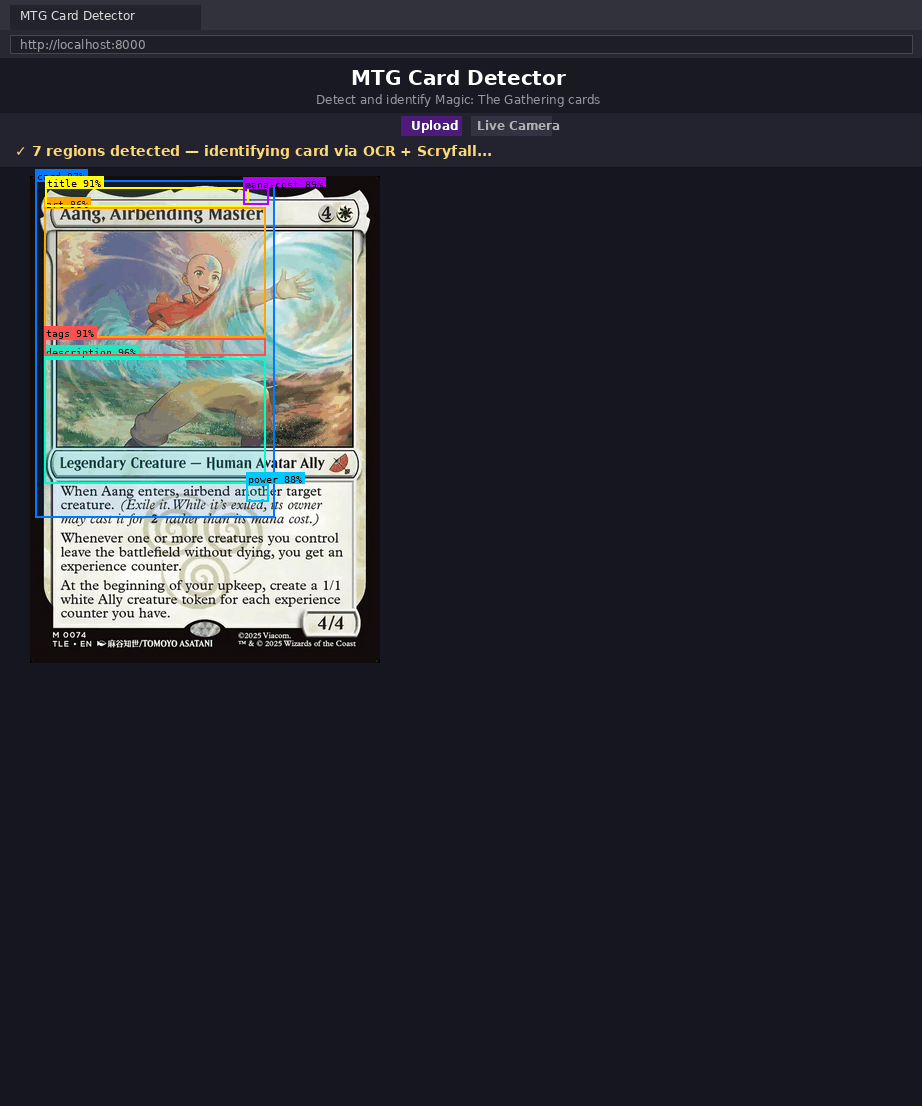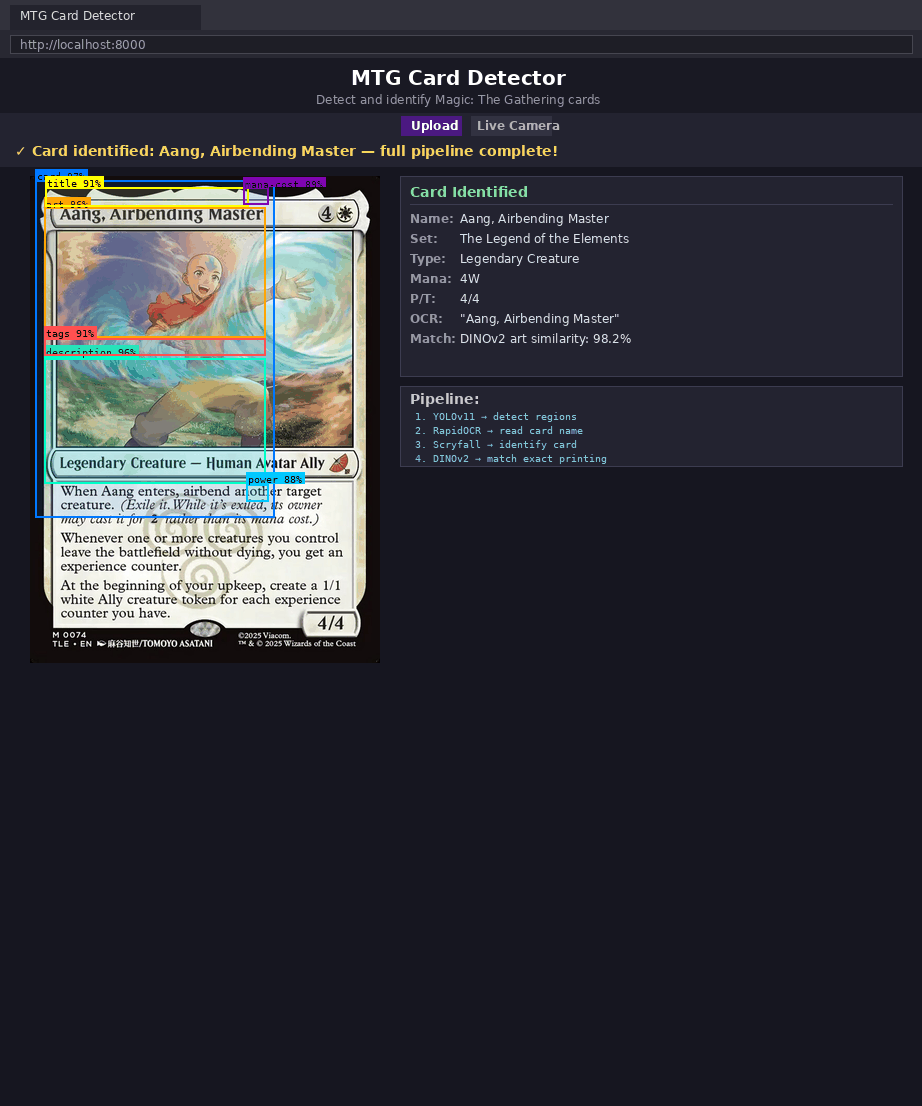
Stage 3: Scryfall Resolves the Card
Once OCR produces a candidate title, the project calls the Scryfall API for fuzzy lookup and metadata retrieval.
This is a powerful design choice because it outsources a large body of card knowledge to a specialized external service:
- canonical names
- oracle text
- prices
- printings
- images
The local system does not need to model that entire domain from scratch. It only has to turn vision output into a robust lookup query. That is a much narrower job.
Stage 4: DINOv2 Disambiguates Printings
This is where the project becomes especially interesting.
Text is often enough to identify the card. It is not always enough to identify the printing. Different printings can share the same name and rules text while still differing in art, set, and numbering.
That is why the art detection class matters so much. The art crop becomes the input to a DINOv2 embedding comparison against candidate printings.
Conceptually:
- crop the art region from the input image
- embed that crop into vector space
- embed candidate printing art images
- compare vectors with cosine similarity
- select the closest match
That is an elegant example of mixing specialized models instead of demanding one model do everything.

Error Propagation Is the Real Challenge
Pipelines are powerful because they decompose a hard problem. They are also dangerous. Every stage can compound failure.
This means the project cannot evaluate stages in isolation forever. It eventually has to reason about end-to-end reliability. That is where product quality lives.
The practical implication is simple. The best improvement is not always in the most glamorous stage. A slightly better crop can beat a much fancier matching model if it removes noise early.
Why the Service Split Is Strong
The web/services/ directory reflects sound decomposition:
detection.pyocr.pyscryfall.pyimage_match.py
That structure keeps responsibilities narrow and debuggable. If card resolution fails, the team can inspect which boundary broke:
- Did detection miss the title?
- Did OCR misread the crop?
- Did Scryfall return poor fuzzy matches?
- Did DINOv2 rank the wrong art highest?
This is exactly how production systems should be designed.
The Best Architectural Lesson
The project succeeds here because it does not confuse "AI-powered" with "single-model." It composes the right specialized tools:
- detector for spatial structure
- OCR for text
- API lookup for canonical metadata
- embedding model for visual similarity
That compositional mindset is more valuable than any single library choice.
Conclusion
The final user experience feels simple because the architecture is layered, not because the problem is simple.
Detection is the gateway. Identification is the orchestration that follows. That is the difference between a model demo and a working product.

In the final article, we look at how this system is exposed through the web application and what it takes to ship it responsibly.
Further Reading
- Full pipeline walkthrough:
docs/solution.md - Web service code:
web/services/detection.py - OCR service:
web/services/ocr.py - Scryfall service:
web/services/scryfall.py - Art matching service:
web/services/image_match.py - Scryfall API docs: https://scryfall.com/docs/api
- DINOv2 paper: https://arxiv.org/abs/2304.07193
- RapidOCR: https://github.com/RapidAI/RapidOCR