

Most ML projects look complete when the model works. Most users disagree.
The final job is not training. It is shipping. That means packaging the pipeline behind stable interfaces, exposing it through a usable frontend, handling failure gracefully, and creating a path for the system to improve after release.
The Web Layer Is Where the Project Becomes Real
The web/ directory is the bridge from internal scripts to a product surface:
web/app.pyorchestrates the APIweb/services/encapsulates the pipeline dependenciesweb/static/provides the browser experience
That separation matters because it keeps the product boundary explicit. Training scripts can evolve independently from the service layer as long as the served model contract stays stable.
FastAPI as the Product Shell
FastAPI is a practical choice for this project because it gives the pipeline:
- explicit request/response boundaries
- easy integration with Python-based ML dependencies
- clean service composition
- a path to validation, logging, and future monitoring
The important insight is that the API does not merely expose a detector. It exposes the full orchestration result. That keeps frontend complexity low and centralizes pipeline logic where it can be tested and observed.

The Frontend Has Two Jobs
The static frontend supports both upload and live camera flows.
Those two modes imply different product concerns:
- upload mode optimizes for clarity and reproducibility
- live mode optimizes for responsiveness and trust
A good vision product should show users enough intermediate evidence to trust the result. Bounding boxes, cropped regions, and panel details help a lot here. The repo already leans in that direction.
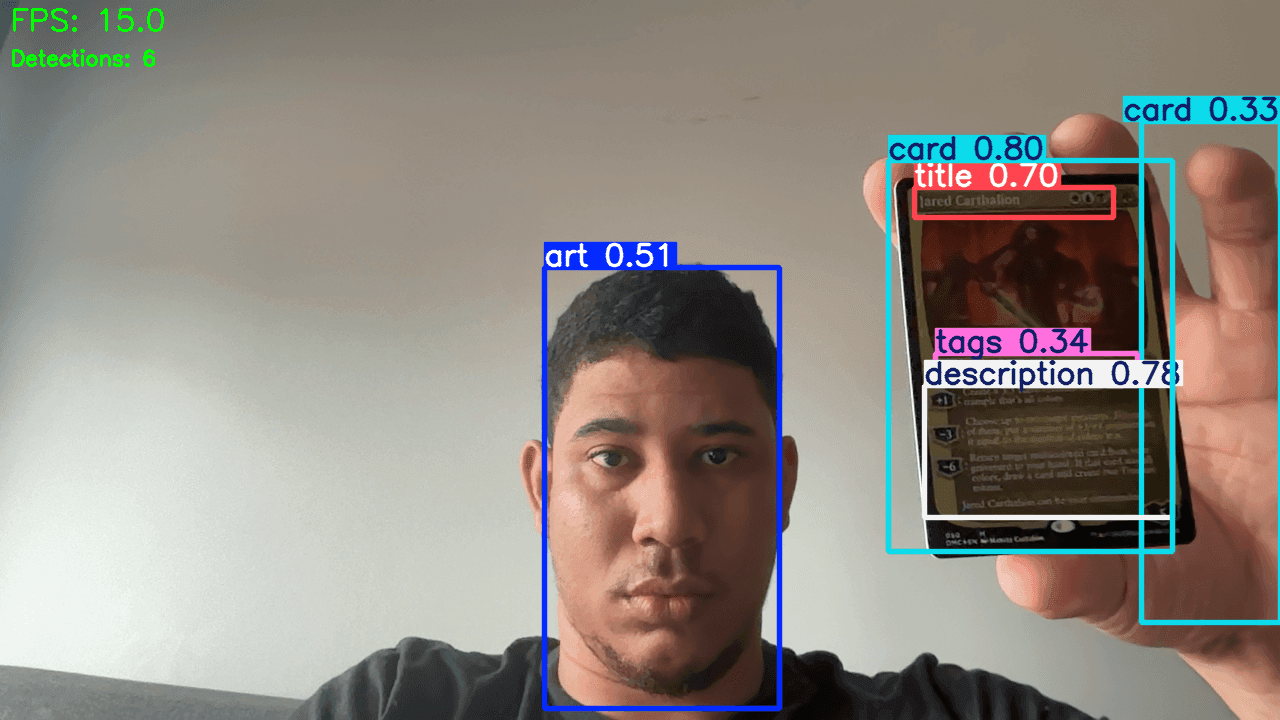
Operational Boundaries Matter
This system relies on several external or heavyweight components:
- model inference
- OCR runtime
- Scryfall availability
- DINOv2 embedding comparisons
That creates operational questions the codebase should keep answering:
- Which steps are local and which are remote?
- What happens when the API lookup fails?
- How should timeouts and retries behave?
- Which intermediate results can still be shown when a later stage fails?
These are shipping questions, not academic questions.
The Correction Loop Belongs in Production Thinking
One of the strongest parts of the repo is the explicit annotation-correction workflow. That should not be treated as a side document. It is the system's learning loop.
This is the mature answer to model drift and blind spots. You do not just train once and hope. You build the path by which the product teaches the dataset where it is weak.

Limitations Should Be Stated Plainly
The repo already contains enough information to state realistic limitations:
- small regions are harder to localize tightly
- annotation quality appears to limit strict metrics
- OCR quality depends on clean title crops
- printing disambiguation is only as strong as candidate retrieval and art similarity
- cloud scaling can cost more than it helps if the data ceiling is unchanged
That kind of honesty is a strength. Users trust systems more when their limits are legible.
Where the Next Wins Probably Are
If I were continuing this project, the highest-value next steps would likely be:
- improve or correct labels for small difficult classes
- add more targeted examples for real webcam edge cases
- instrument the end-to-end pipeline for stage-by-stage failure rates
- evaluate latency and caching around Scryfall and art matching
- measure real user errors, not only validation metrics
Notice how few of those ideas begin with "train a much bigger model." That is deliberate.

Conclusion
Shipping a vision system means accepting that the model is only one layer in a larger contract with the user.
This project gets that right. It trains a strong detector, but it also builds the scripts, services, correction workflow, and frontend surface required to make the result usable. That is why it is a compelling engineering project and not just a benchmark entry.
Further Reading
- Full solution document:
docs/solution.md - Annotation correction workflow:
docs/annotation-correction.md - Architecture overview:
docs/architecture.md - FastAPI docs: https://fastapi.tiangolo.com/
- ONNX Runtime: https://onnxruntime.ai/